Designing a Simple File System
202309300916
Status: #idea
Tags: DSTN
Designing a Simple File System
- Think of the data structures and access methods of a file system
Overall Organisation
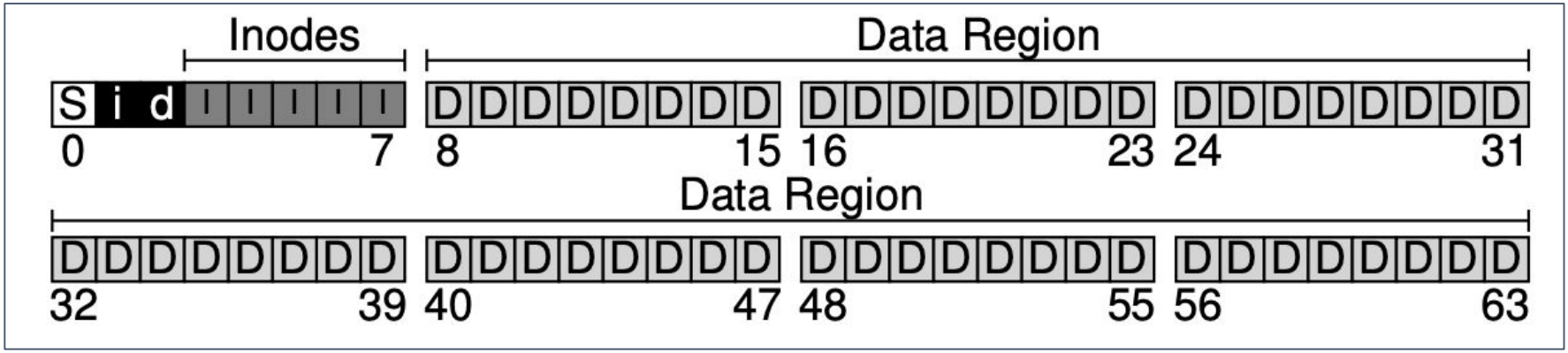
- Divide the disk into blocks
- Most blocks are used to store user data (data region)
- File metadata is stored in inodes in the inode table
- Data/inode bitmap stores the last free block/inode
- Superblock
- How many inodes/data blocks
- Where does the inode table begin
- Magic number to denote the file system type
OS only knows the inode of / and the inode of the pwd
Making a file system mkfs
- Used to build a Linux file system on a device (often a hard disk partition)
- Simply writes an empty file system, starting with root directory onto that partition
hdX was traditionally used for IDE drives. sdX is typically used for SCSI/SATA drives
Mounting a file system mount
- Once a file system is created, it needs to be accessible from the uniform file-system tree
- Takes an existing directory as a target mount point and essentially pastes a new file system onto the directory tree at that point
mountunifies all file systems into a single tree, making naming uniform and convenient
Inode
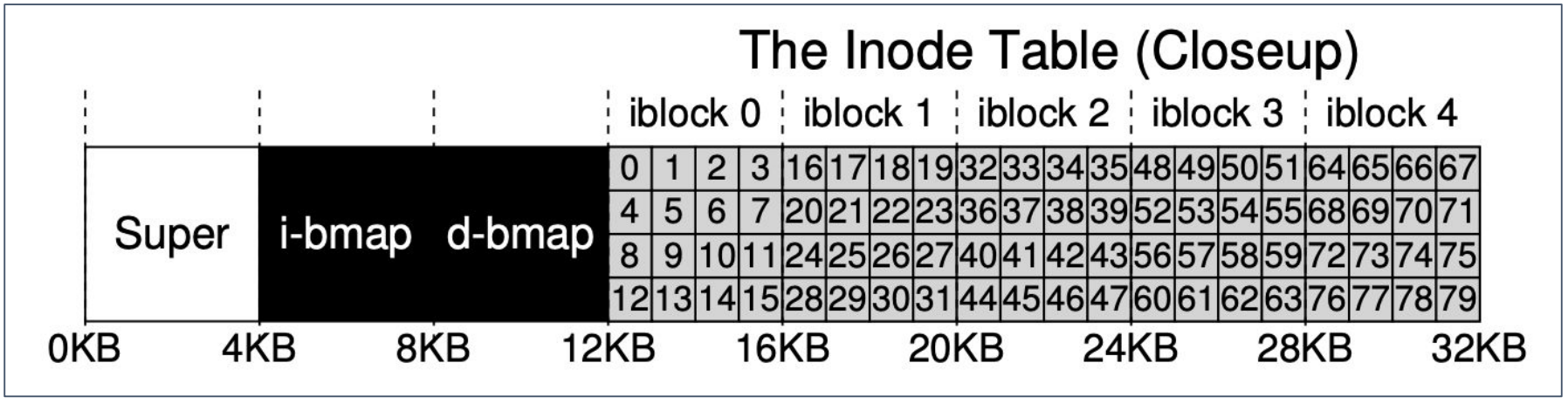
- Each inode is implicitly referred to by its i-number
ext2/3 has multi-level indexing.
Each of the 15 data blocks act as pointers to other data blocks. This allows it to store files
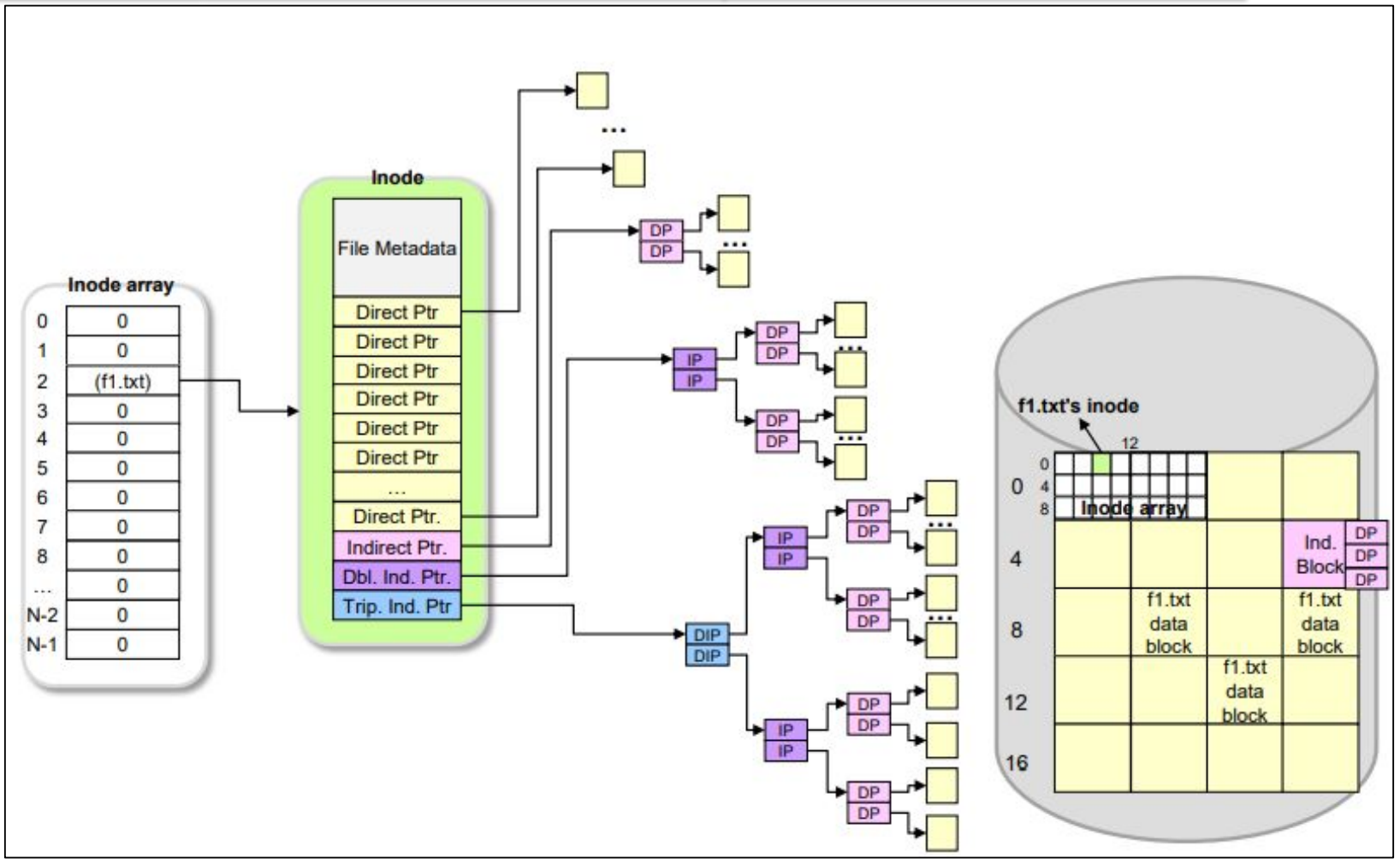
Each inode has 12 direct pointers, 1 indirect block address, 1 double-indirect block address and 1 triple-indirect block address
Why use an imbalanced block allocation tree?
- Most files are small - More direct pointers
- Most bytes are stored in large files - A few big files use most of the space
- File systems are roughly half-full
- Directories are typically small - Most have <20 entries
Extent-based Approach vs Pointer-based Approach
| Pointer-based approach | Extent-based approach |
|---|---|
| Most flexible | Less flexible |
| Use a large amount of metadata per file (particularly for large files) | More compact |
| Works when there is enough free space on disk and files can be laid out contigously |
Link-based Approach (FAT)
- Inode stores a pointer to first block of a file
- To handle larger files, another pointer is added at the end of the data block
- Should have an in-memory file allocation table
- Table is indexed by block address of the starting block of the file
- A null value indicates the end of the file
- Some other marker could indicate if a block is free
- Can effectively do random access
- Because we don't need to follow pointers
Directory Organisation
- The data block of a directory contains
(filename, inode_number)pairs - Might be a simple linear list of directory entries
- Might have a more complex structures like B-Trees
When creating a file, based on the name, a suitable reclen is used. This indicates the maximum length for the file name.
TODO: This is relevant to allow for easy reuse of old inodes
Free Space Management
- Bitmaps
- Can easily check for
contiguous blocks when creating new files
- Can easily check for
- Free list
- Super block stores pointer to first free block
- Each time a block is used, the position of the head of the list is updates
- Complex data structures
- XFS uses B-Trees for inodes also
Reading a file
open("/path/to/directory/foo.txt", O_RDONLY);
- Find the inode of the root
- Read the data block to find the next step in the apth
- Repeat till we reach the desired file
- Read the appropriate inode
- Read the data block of the directory, to find the next suitable inode
- Read the inode of the file into memory
- FS does a permission check
- Allocates a file descriptor for this process in OFT
Every read call, the inode will be written to. This is used to update the access time metadata
Reducing File System I/O Costs
- Caching
- Static partitioning
- Fixed size in memory to hold popular blocks
- Employs LRU strategies to evict blocks
- Easier to implement
- Predictable performance benefits
- Might be wasteful
- Dynamic partitioning
- Virtual memory and file system pages use a predetermined size (unified page cache)
- Harder to implement
- Better resource utilisation
- Static partitioning
First open call will generate a lot of I/O traffic. Subsequent calls will result in a cache hit and no disk I/Os will be performed.
- Caching of write operations
- Syncronous/write-through cache writes to disk immediately
- Asyncronous/write-back cache stores the dirty (updates) block in memory and writes back after a delay. This is called write buffering