Hashing Schemes
202406232235
Status: #idea
Tags: CMU Advanced Database Systems
Hashing Schemes
Chained Hashing
- Collision leads to a bucket which is a linked list
- Optimization (from Hyper)
- Hardware only uses a 48-bit pointer
- In the extra 16-bits, store put a bloom filter
Open-Addressing Hashing
- Single giant table of slots
- If not free, then scan linearly till next free slot
- If we come back to the same slot, resize the table
- Different probing schemes
- Linear-> Scan sequentially
- Quadratic
- Jump to slots based on a quadratic equation
- Prevents clustering
- Hash table should be
in linear probing to get good performance
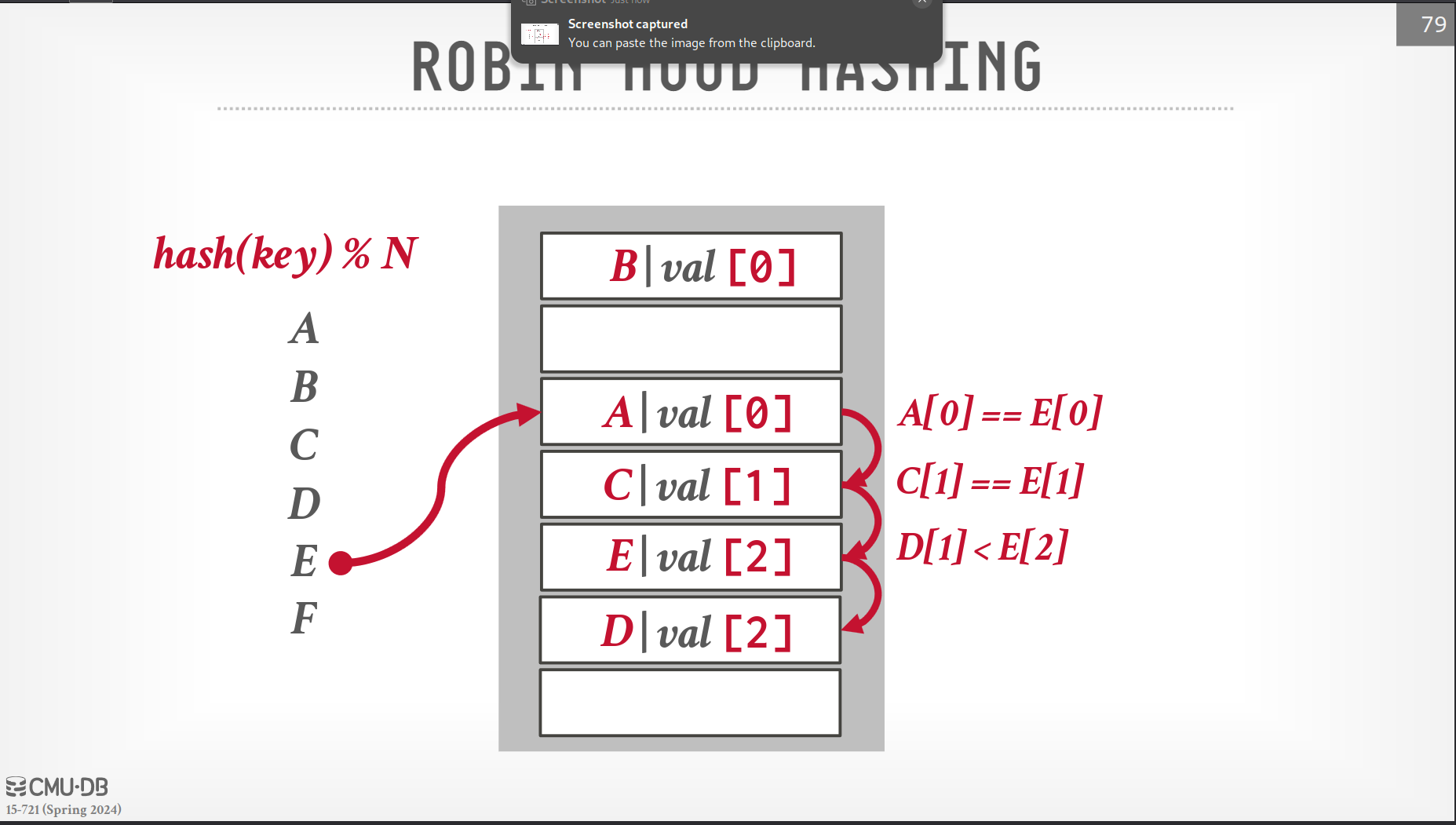
Robin-Hood Hashing
- Variant of linear probe hashing
- Steal slots form 'rich' keys and give them to 'poor' keys
- Each key tracks its distance from its optimal position
- Minimize average distance that a key is from its desired slot
- Adds cost to build side, so that during probing, time is saved
Hopscotch Hashing
- Keys can move between positions in a 'neighborhood'
- A neighborhood is a contiguous section in the HT
- Size of the neighborhood is a configurable constant (ideally a single cache line)
- A key is guaranteed to be in its neighborhood or not exist
- If it is in a cache line, then the cost of a lookup in a neighborhood is same as the cost of looking up the actual key (because the full neighborhood would be in the cache)
Cuckoo Hashing / Double Hashing
- Use multiple hash functions
- On insert, check every hash function and pick first function which leads to a free slot
- If no table has a free slot, evict the element in its slot, and rehash this element. Repeat till all elements are settled
- Ensure to keep a visited array, for eviction. If cycle occurs, resize HT
- Lookups are always
- Good for read-heavy workloads