What makes Kafka & Redis so fast
202407270931
Status: #idea
Tags: e6data
What makes Kafka & Redis so fast?
Kafka
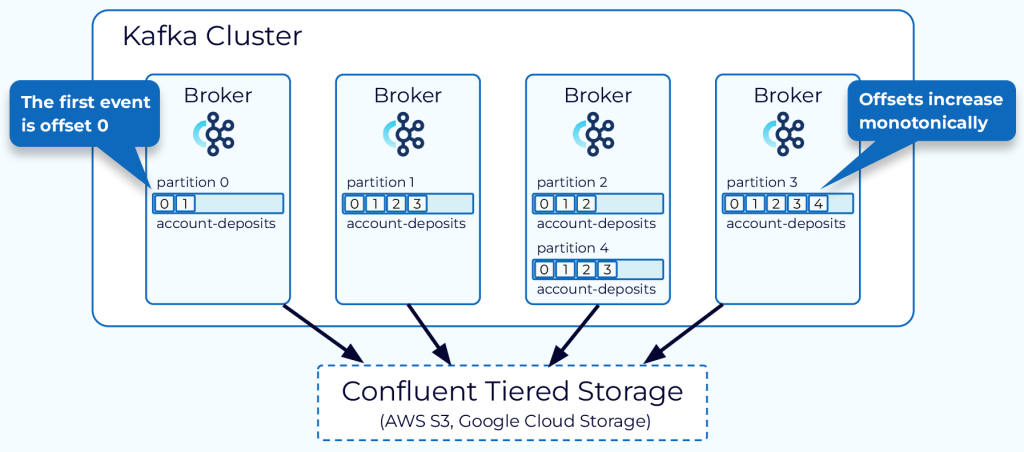
- Kafka’s data is spread across multiple machines
- Partitions
- Data in a topic is spread across partitions which reside on brokers
- Broker
- Hosts all of the data
- Contains multiple partitions
- Essentially a storage service of sort (as Kafka is not in-memory)
- Kafka topics are append-only logs
- Kafka uses the sendfile system call to avoid moving data into user space, and copies directly between 2 file descriptors
- Uses a write-ahead log for consistency to disk
- Use Redis queues for in-memory queuing
Redis
- Multiplexing
- A single thread listens on multiple sockets/file descriptors
Questions
- Kafka
- How to ensure reads are sequential? Do I need a separate disk for each consumer at different offsets to get maximum performance?